데이터 분석을 하기 위한 첫 걸음이 엑셀 파일의 데이터를 파이썬으로 불러들이는 것입니다. 엑셀 파일을 위한 라이브러리의 종류와 사용방법에 대해 알아보도록 하겠습니다.
파이썬에서 엑셀 파일 다룰 때 주의사항
엑셀 파일 가공 금지
파이썬으로 데이터 분석 시 엑셀 파일에 있는 내용을 불러들일 겁니다. 이때 엑셀에서 파일의 내용을 가공하지 마세요. 엑셀 파일 내부의 내용을 엑셀 프로그램을 이용해 수정하지 말라는 겁니다.
가공되지 엑셀 파일의 데이터는 현장에서 바로 얻게 되는 1차 버전의 포맷입니다. 데이터 분석을 할 때는 이 포맷을 유지한 상태로 프로그래밍을 해야 데이터에 대한 이해도를 높일 수 있습니다.
엑셀을 가공 했다면 현장에서 데이터를 얻을 때 마다 매번 엑셀 수정 작업을 해야 합니다. 파이썬에서 데이터 전처리 코딩을 하게 되면 추가로 얻은 데이터를 바로 분석할 수 있을 겁니다.
Ref 파일을 이용한 용량 최소화
분석하려는 엑셀 파일에는 필요없는 데이터도 있을 수 있습니다. 엑셀 파일의 칼럼명을 관리할 수 있는 별도의 파일을 만든다면 데이터를 불러 들일때 필요한 용량만 사용할 수 있습니다.
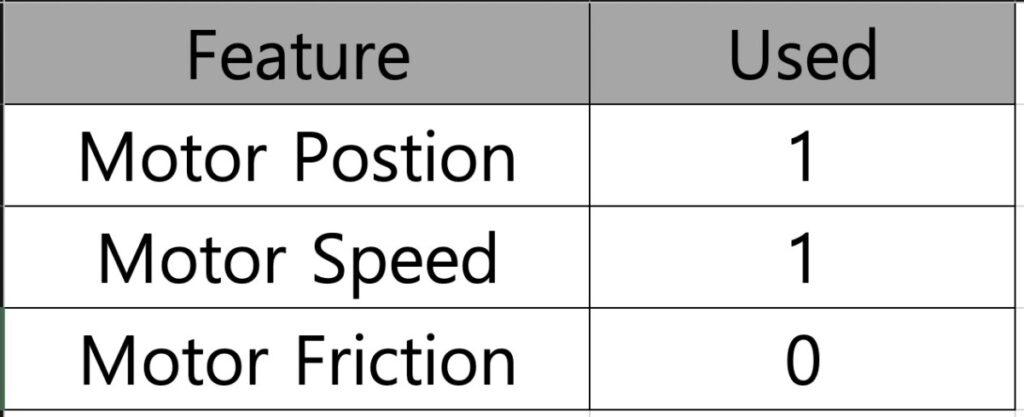
위는 레퍼런스 파일 샘플입니다. ‘Feature’는 데이터 종류를 의미하며, ‘Used’는 엑셀 내 데이터를 읽을지(1), 무시할 지(0)를 선택할 수 있습니다.
df = pd.read_excel('data.xlsx')
ref = pd.read_excel('ref.xlsx')
used_col = ref[ref['Used']==1].values
data = df[used_col]업무 시 데이터 분석을 하게되면 정말 많은 ‘feature’들을 보게 됩니다. 레퍼런스 파일을 잘 관리하는 습관을 갖게 되면 데이터를 보는 시야도 많이 넓어지게 될 겁니다.
데이터 폴더 내 파일명 읽기
vscode 에서 ‘000 TEST’폴더를 지정하고 그 안에 ‘data’ 폴더를 만들어 불러들일 ‘csv’파일을 넣어놨습니다.
파일의 경로를 ‘file_path’에 넣었습니다. 맥북 기준으로 하위 폴더를 지정할 때는 ‘./data/’를 사용합니다. 윈도우에서는 ‘.\\data\\’로 작성합니다.
‘os.listdir()’은 해당 경로 안에 있는 파일의 이름을 리스트로 입력시켜줍니다. 정렬(sort)을 하지 않을 경우 파일의 순서에 상관없이 리스트가 만들어집니다. 정렬을 해 준다 해도 ‘1’을 우선하기 때문에 1 다음에 10이 나오는 현상이 생깁니다.
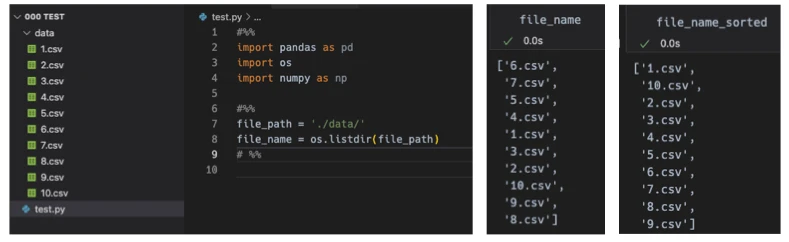
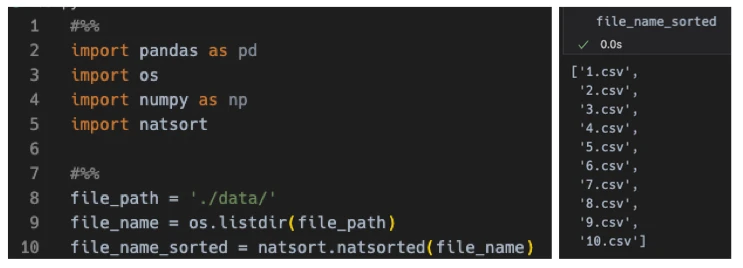
정확한 정렬을 위해서는 ‘natsort’ 라이브러리를 사용할 수 있습니다. ‘natsort.natsorted()’를 사용하게 되면 아래와 같이 잘 정렬됩니다.
데이터 파일들을 ‘data’폴더에 넣은 후 각 파일명을 얻었다면 아래와 같이 각 파일 내 데이터를 데이터프레임으로 갖고 올 수 있습니다. ‘file_name_sorted[0]’은 ‘1.csv’ 파일을 지칭합니다.
data_1 = pd.read_csv(file_path + file_name_sorted[0])‘file_name_sorted’가 리스트이기 때문에 ‘[]’안에 숫자를 바꾸면 폴더 내 다른 파일을 읽을 수 있습니다. 또한 ‘[i]’로 하고 ‘for’문을 돌리면 모든 파일을 동시에 읽을 수 있습니다.
사내 보안 걸린 엑셀 파일
Pandas로 엑셀을 읽을 경우
회사마다 보안의 정도가 다르기 때문에 일반적으로는 pandas 라이브러리를 사용해서 엑셀파일을 읽게 합니다. 만일 아래와 같은 error가 발생한다면 보안 문제를 의심해봐야 합니다.
ValueError: File is not a recognized excel file
xlwings 라이브러리 사용
전 회사에서는 pandas로 데이터 분석 코드를 작성했지만 이직 후 위의 에러가 발생하면서 엑셀을 읽지 못하는 문제에 직면하게 됐습니다. 이때 알아낸 방법이 ‘xlwings’ 라이브러리를 사용하는 것이었습니다.
import xlwings as xw
book = xw.Book(file_path + file_name_sorted[0])
data = book.sheets(10.used_range.options(dp.DataFrame, index=False).value위쪽의 pandas를 이용해 엑셀 파일을 읽을 때와는 많이 다르게 사용됩니다. 위의 코드를 사용하면 사내 보안이 걸린 파일도 읽을 수 있을 겁니다.
여러 엑셀 파일 빠르게 취합하기
지금까지 한 개의 엑셀 파일을 데이터 프레임으로 입력하는 방법을 얘기했습니다. 파일 하나에 모든 데이터가 있으면 좋겠지만 실상은 시간별, 날짜별 파일이 생성되기 때문에 많은 양의 데이터 분석을 위해서는 파일을 취합해야 합니다.
데이터 폴더 안에 여러개의 파일을 넣고 파일명을 리스트로 만든 이유가 여러개의 파일을 하나의 데이터 프레임으로 만들기 위한 준비를 한 겁니다.
data_list = []
for fn in file_name_sorted:
data_list.append(pd.read_csv(file_path + fn))
data = pd.concat(data_list)위의 방식은 각각의 파일을 데이터프레임으로 ‘data_list’에 넣고 마지막에 ‘concat’ 명령을 사용해 리스트 안에 있는 여러개의 데이터프레임을 하나로 취합하는 겁니다.
물론 ‘for’문 안에서 데이터프레임을 지속적으로 확장하는 방식도 있습니다. 하지만, 데이터프레임을 계속 메모리에 넣고 있어야 하기 때문에 속도가 느려지게 됩니다.
여러개의 파일을 하나의 데이터프레임으로 만들었다면 이것을 다시 하나의 엑셀 파일로 내보낼 수 있습니다. 이러한 코딩으로 여러 엑셀 파일을 하나로 취합하는 프로그램을 작성할 수 있습니다.
data.to_csv('merged_data.csv')파이썬을 이용한 엑셀 파일 다루기를 마치며
파이썬으로 데이터를 분석할 때 가장 많이 다루는 파일 형식이 바로 ‘csv’일 겁니다. 또는 ‘xlsx’도 있긴 합니다. 오늘은 두 형식의 파일을 데이터프레임으로 갖고 오는 방법에 대해 알아봤습니다.
회사에서는 보안 프로그램이 자동으로 엑셀 파일을 암호화하기 때문에 판다스 라이브러리만으로 엑셀 파일을 파이썬으로 갖고 오지 못할 수도 있습니다. 이를 위해 ‘xlwings’ 라이브러리를 사용하게 됩니다.
‘file_path’와 ‘file_name’으로 파일 경로와 파일명을 관리하는 프로그램을 짤 수 있다면 파일 취합용 프로그램도 쉽게 작성할 수 있습니다. 이러한 코드들을 이용해 회사 업무를 자동화 해보세요.